機
器
人
字串的選取
在上個章節中,我們討論了一些有關字串的基本知識—字串的建立、運算等。但是你知道嗎?字串其實與列表有很多的相似之處,甚至我們可以說,字串就是一個有很多字的列表!因為這個特點,很多程式語言都有有趣而實用的字串功能,接下來,讓我們來研究一下 Python 字串的選取!
字串的位置編號
在程式中,字串中的每一個字都有自己的編號位置(index)。在大多數現代的高階程式語言中,字串中的文字從左側至右側,分別編為 0、1、2、3…;有些程式語言則從 1 開始編號。我們現在所熟知的 Python,與多數的語言一樣,採用從 0 開始編號的系統(zero-based indexing)
現在,讓我們馬上來建立一個字串看看吧!我們將「a fox」這段文字賦予給一個變數,並且將它 print 出來:
stringA = "a fox"
print(stringA)
我們將會得到這樣的結果:
a fox
現在,我們確定這個宣告變數的過程是沒有問題的,那就可以來討論關於字串編號的問題了。剛剛說過,字串中的每一個字都有自己獨特的編號,而且這些編號是從 0 開始計算,因此我們可以推測,「a fox」中的第一個字(a)編號為 0,第二個字( )編號為 1,第三個字(f)編號為 2,以此類推。
要怎麼確定這樣的想法是不是對的呢?我們可以這樣來驗證:
print(stringA[0])
這樣我們可以得到:
a
這個「a」其實就是「a fox」中 0 號位置的「a」,可見我們剛剛的推測是正確的。我們接著來回顧一下,在剛剛的範例程式中發生了什麼事:

我們剛才 print 出了 stringA[0],代表變數 stringA 的 0 號位置,也就是「a fox」中的第一個字,「a」。此處我們得到一個重點結論:在字串後面加上 [i]可以表示字串中特定位置的某個字( i 為編號)。
除此之外,在 Python 中,字串選取的編號也可以是負值,如下圖所示:
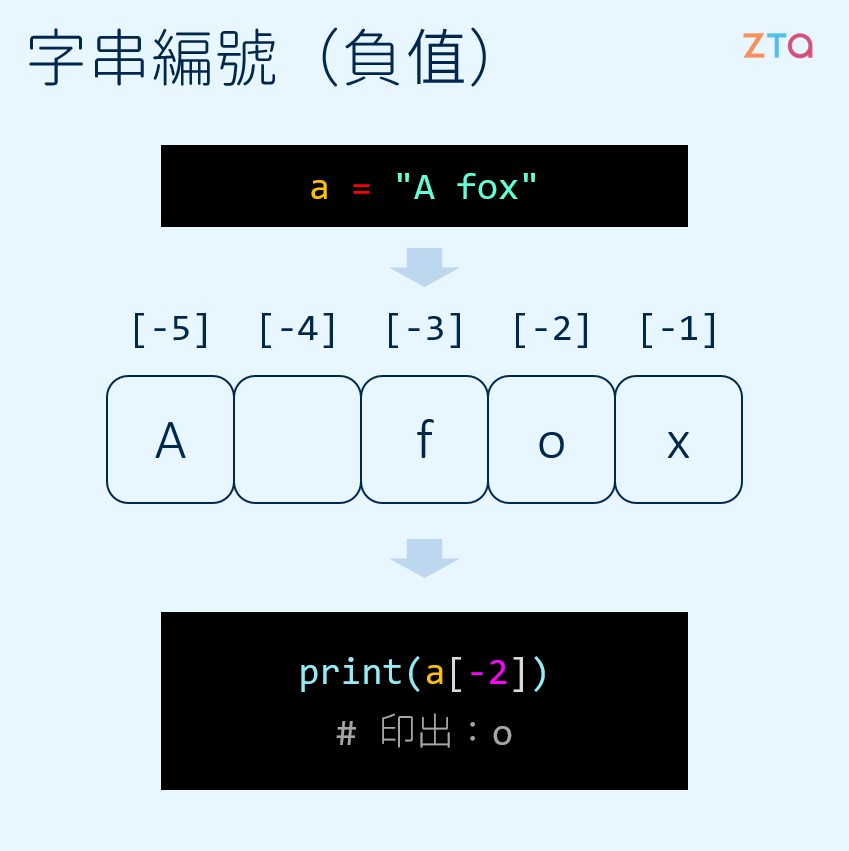
這裡我們就有一個很大的問題了:如果可以使用正值來選取字串,那為何要麻煩自己,搞一個負值的字串編號呢?其實答案很簡單,有時候我們想要選取字串的最後一個字元,但是卻不知道字串的長度是多少。當然,我們可以使用 len() 來獲取字串長度,但如果可以直接使用 stringA[-1] 的形式來選取,就簡單多了!
[x:y] 選取
[i] 可以用來獲取字串中特定位置的文字,但如果今天要獲取的是字串中的另一段字串,這個方法就不可行了。因此,Python 有另一種在字串中選取的方法,大概可以表達成 [x:y]
讓我們回到剛剛的那個例子:
stringA = "a fox"
我們試著使用這種選取方法:
print(stringA[0:4])
我們將會得到這樣的結果:
a fo
為什麼是這樣?讓我們來分析一下。在程式中,[0:4] 選取了字串中從位置 0 開始(包含 0),至位置 4 結束(不包含 4)的字串,也就是選取了 0、1、2、3 四個位置的四個文字。因此,在 print() 時,電腦印出了「a fo」四個文字(包含中間的空格)。
這麼一來,我們可以做一個小小的結論—當選取了字串中 [x:y] 這段文字時,直覺地我們會有兩種想法:
- 選取位置 x 開始至 y 結束(包含 x,但不包含 y)
- 選取從位置 x 開始的 (x-y) 個字元
另外,x 和 y 兩個數字其實可以省略不寫,讓我們看看下面兩個例子:
a = "Hi there"
print(a[0:4])
print(a[:4])
將會輸出:
Hi t
Hi t
由此我們可之,當冒號 : 前的數字 x 被省略時,Python 將會自動將其補上一個 0。省略後的程式比為省略前的程式來的更簡單易懂,例如,當我們看到 a[:4] 時,可以直覺地想到「在位置 4 以前的所有字元」,是不是相當地簡潔呢?
而如果今天所省略的是冒號 : 之後的數字,例如:
b = "Hello there"
print(b[4:len(b)])
print(b[4:])
將會得到:
o there
o there
省略冒號 : 之後的數字,Python 將會自動地補上字串的長度,也就是說,當我們看到 b[4:] 時,也可以直覺地想到「從位置 4 開始所有剩下的字元」,可說是相當方便。
[x:y:d] 選取
除了使用 [x:y] 來選取字串中的片段之外,Python 還提供了一個相當有趣的選字方法:[x:y:d] 選取,其中,d 所代表的是選字位置的公差。聽不懂嗎?讓我們馬上進入這個例子:
a = "ThisStringIsLong"
print(a[2:11])
將會輸出:
isStringI
目前為止,都是我們剛剛所學過的東西,那麼,讓我們在選取字串的 [] 中加入第三個數字 d:
a = "ThisStringIsLong"
print(a[2:11:2])
螢幕上將會得到:
iSrnI
為什麼是這樣?記得我們剛剛所選取的 [2:11] 嗎?我們得到的結果是「isStringI」。現在,當我們選取 [2:11:2] 時,也是在選取同個範圍的字串,但是我們告訴電腦「每 2 個文字才選取一次」。因此,電腦在選取「isStringI」時,從第一個字 i 開始,每隔兩個字元選取一次,分別得到 i、S、r、n、I 五個字母。
讓我們看看第二個類似的例子,並且用圖片來解釋選取的過程:
a = "a fox here"
print(a[2:8:2])
將會得到:
fxh

最後,讓我們來看看,選取 [x:y:d] 時,省略 x 和 y,並且將 d 設為 -1 的字串選取會有什麼樣的結果:
m = "a cool string"
print(m[::-1])
將會印出:
gnirts looc a
是不是真的很酷呢!這麼一來,如果要將一個字串反轉,只需要使用 [::-1] 便可以快速地達成了!